# Import the following libraries
# For fetching from the Raster API
import requests
# For making maps
import folium
import folium.plugins
from folium import Map, TileLayer
# For talking to the STAC API
from pystac_client import Client
# For working with data
import pandas as pd
# For making time series
import matplotlib.pyplot as plt
# For formatting date/time data
import datetime
# Custom functions for working with GHGC data via the API
import ghgc_utilsAir-Sea CO₂ Flux, ECCO-Darwin Model v5
Global, monthly average air-sea CO₂ flux at ~1/3° resolution from 2020 to 2022.
Access this Notebook
You can launch this notebook in the US GHG Center JupyterHub (requires access) by clicking the following link: Air-Sea CO₂ Flux, ECCO-Darwin Model v5. If you are a new user, you should first sign up for the hub by filling out this request form and providing the required information.
If you do not have a US GHG Center Jupyterhub account, you can access this notebook through MyBinder by clicking the button below.
![]()
Table of Contents
Data Summary and Application
- Spatial coverage: Global
- Spatial resolution: 1/3°
- Temporal extent: January 2020 - December 2022
- Temporal resolution: Monthly
- Unit: Millimoles of CO₂ per meter squared per second (mmol m²/s)
- Utility: Climate Research, Oceanography, Carbon Stock Monitoring
For more information, visit the Air-Sea CO₂ Flux, ECCO-Darwin Model v5 data overview page.
Approach
- Identify available dates and temporal frequency of observations for the given collection using the US Greenhouse Gas Center (GHGC) Application Programming Interface (API)
/stacendpoint. The collection processed in this notebook is the Air-Sea CO₂ Flux, ECCO-Darwin Model v5 product. - Pass the STAC item into the raster API
/collections/{collection_id}/items/{item_id}/{tile_matrix_set_id}/tilejson.jsonendpoint. - Using
folium.plugins.DualMap, visualize two tiles (side-by-side), allowing time point comparison. - After the visualization, perform zonal statistics for a given polygon.
About the Data
Air-Sea CO₂ Flux, ECCO-Darwin Model v5
The ocean is a major sink for atmospheric carbon dioxide (CO₂), largely due to the presence of phytoplankton that use the CO₂ to grow. Studies have shown that global ocean CO₂ uptake has increased over recent decades, however, there is uncertainty in the various mechanisms that affect ocean CO₂ flux and storage and how the ocean carbon sink will respond to future climate change.
Because CO₂ fluxes can vary significantly across space and time, combined with deficiencies in ocean and atmosphere CO₂ observations, there is a need for models that can thoroughly represent these processes. Ocean biogeochemical models (OBMs) can resolve the physical and biogeochemical mechanisms contributing to spatial and temporal variations in air-sea CO₂ fluxes but previous OBMs do not integrate observations to improve model accuracy and have not been able to operate on the seasonal and multi-decadal timescales needed to adequately characterize these processes.
The ECCO-Darwin model is an OBM that assimilates Estimating the Circulation and Climate of the Ocean (ECCO) consortium ocean circulation estimates and biogeochemical processes from the Massachusetts Institute of Technology (MIT) Darwin Project. A pilot study using ECCO-Darwin was completed by Brix et al. (2015) however, an improved version of the model was developed by Carroll et al. (2020) in which issues present in the first model were addressed using data assimilation and adjustments were made to initial conditions and biogeochemical parameters. The updated ECCO-Darwin model was compared with interpolation-based products to estimate surface ocean partial pressure (pCO2) and air-sea CO₂ flux. This dataset contains the gridded global, monthly mean air-sea CO₂ fluxes from version 5 of the ECCO-Darwin model.
The data available in the US GHG Center hub are available at ~1/3° horizontal resolution at the equator (~18 km at high latitudes) from January 2020 through December 2022. For more information regarding this dataset, please visit the Air-Sea CO₂ Flux, ECCO-Darwin Model v5 data overview page.
Terminology
Navigating data via the US GHGC API, you will encounter terminology that is different from browsing in a typical filesystem. We’ll define some terms here which are used throughout this notebook.
catalog: All datasets available at the/stacendpointcollection: A specific dataset, e.g. Air-Sea CO₂ Flux, ECCO-Darwin Model v5item: One data file (i.e. granule) in the dataset, e.g. one monthly file of fluxesasset: A variable available within the granule, e.g. CO₂ fluxesSTAC API: SpatioTemporal Asset Catalogs - Endpoint for fetching the data itselfRaster API: Endpoint for fetching data, for imagery and statistics
Install the Required Libraries
Required libraries are pre-installed on the US GHG Center Hub, except the tabulate library. If you need to run this notebook elsewhere, please install the libraries by running the following command line:
%pip install requests folium rasterstats pystac_client pandas matplotlib tabulate –quiet
Querying the STAC API
The libraries above allow better execution of a query in the US GHG Center Spatio Temporal Asset Catalog (STAC) API, where the granules for this collection are stored. You will learn the functionality of each library throughout the notebook.
STAC API Collection Names
Now, you must fetch the dataset from the STAC API by defining its associated STAC API collection ID as a variable. The collection ID, also known as the collection name, for the Air-Sea CO₂ Flux, ECCO-Darwin Model v5 dataset is eccodarwin-co2flux-monthgrid-v5.
# Provide the STAC and RASTER API endpoints
# The endpoint is referring to a location within the API that executes a request on a data collection nesting on the server.
# The STAC API is a catalog of all the existing data collections that are stored in the GHG Center.
STAC_API_URL = "https://earth.gov/ghgcenter/api/stac"
# The RASTER API is used to fetch collections for visualization
RASTER_API_URL = "https://earth.gov/ghgcenter/api/raster"
# The collection name is used to fetch the dataset from the STAC API. First, we define the collection name as a variable
# Name of the collection for ECCO Darwin CO₂ flux monthly emissions
collection_name = "eccodarwin-co2flux-monthgrid-v5"# Fetch the collection from the STAC API using the appropriate endpoint
# The 'pystac_client' library makes an HTTP request
catalog = Client.open(STAC_API_URL)
collection = catalog.get_collection(collection_name)
# Print the properties of the collection to the console
collection- type "Collection"
- id "eccodarwin-co2flux-monthgrid-v5"
- stac_version "1.1.0"
- description "Global, monthly average air-sea CO₂ flux (negative into ocean) at ~1/3° resolution from 2020 to 2022. Data are in units of millimoles of CO₂ per meter squared per second (mmol m²/s). Derived using the ECCO-Darwin model v5, which is an ocean biogeochemical model that assimilates Estimating the Circulation and Climate of the Ocean (ECCO) consortium ocean circulation estimates and biogeochemical processes from the Massachusetts Institute of Technology (MIT) Darwin Project."
links[] 5 items
0
- rel "items"
- href "https://earth.gov/ghgcenter/api/stac/collections/eccodarwin-co2flux-monthgrid-v5/items"
- type "application/geo+json"
1
- rel "parent"
- href "https://earth.gov/ghgcenter/api/stac/"
- type "application/json"
2
- rel "root"
- href "https://earth.gov/ghgcenter/api/stac"
- type "application/json"
- title "US GHG Center STAC API"
3
- rel "self"
- href "https://earth.gov/ghgcenter/api/stac/collections/eccodarwin-co2flux-monthgrid-v5"
- type "application/json"
4
- rel "http://www.opengis.net/def/rel/ogc/1.0/queryables"
- href "https://earth.gov/ghgcenter/api/stac/collections/eccodarwin-co2flux-monthgrid-v5/queryables"
- type "application/schema+json"
- title "Queryables"
stac_extensions[] 2 items
- 0 "https://stac-extensions.github.io/render/v1.0.0/schema.json"
- 1 "https://stac-extensions.github.io/item-assets/v1.0.0/schema.json"
renders
co2
assets[] 1 items
- 0 "co2"
- nodata "nan"
rescale[] 1 items
0[] 2 items
- 0 -0.0007
- 1 0.0002
- colormap_name "bwr"
dashboard
assets[] 1 items
- 0 "co2"
- nodata "nan"
rescale[] 1 items
0[] 2 items
- 0 -0.0007
- 1 0.0002
- colormap_name "bwr"
item_assets
co2
- type "image/tiff; application=geotiff; profile=cloud-optimized"
roles[] 2 items
- 0 "data"
- 1 "layer"
- title "Air-Sea CO₂ Flux"
- description "Monthly mean air-sea CO₂ flux (negative into ocean)."
- dashboard:is_periodic True
- dashboard:time_density "month"
- title "Air-Sea CO₂ Flux, ECCO-Darwin Model v5"
extent
spatial
bbox[] 1 items
0[] 4 items
- 0 -180.0
- 1 -90.0
- 2 180.0
- 3 90.0
temporal
interval[] 1 items
0[] 2 items
- 0 "2020-01-01T00:00:00Z"
- 1 "2022-12-31T00:00:00Z"
- license "CC-BY-4.0"
summaries
datetime[] 2 items
- 0 "2020-01-01T00:00:00Z"
- 1 "2022-12-31T00:00:00Z"
Examining the contents of our collection under the temporal variable, we see that the data is available from January 2020 to December 2022. By looking at the dashboard:time density, we observe that the data is periodic with monthly time density.
items = list(collection.get_items()) # Convert the iterator to a list
print(f"Found {len(items)} items")Found 36 items# The search function can be used to find data within a specific time frame, e.g. 2022.
search = catalog.search(
collections=collection_name,
datetime=['2021-01-01T00:00:00Z','2022-12-31T00:00:00Z']
)
# Take a look at the items we found
for item in search.item_collection():
print(item)<Item id=eccodarwin-co2flux-monthgrid-v5-202212>
<Item id=eccodarwin-co2flux-monthgrid-v5-202211>
<Item id=eccodarwin-co2flux-monthgrid-v5-202210>
<Item id=eccodarwin-co2flux-monthgrid-v5-202209>
<Item id=eccodarwin-co2flux-monthgrid-v5-202208>
<Item id=eccodarwin-co2flux-monthgrid-v5-202207>
<Item id=eccodarwin-co2flux-monthgrid-v5-202206>
<Item id=eccodarwin-co2flux-monthgrid-v5-202205>
<Item id=eccodarwin-co2flux-monthgrid-v5-202204>
<Item id=eccodarwin-co2flux-monthgrid-v5-202203>
<Item id=eccodarwin-co2flux-monthgrid-v5-202202>
<Item id=eccodarwin-co2flux-monthgrid-v5-202201>
<Item id=eccodarwin-co2flux-monthgrid-v5-202112>
<Item id=eccodarwin-co2flux-monthgrid-v5-202111>
<Item id=eccodarwin-co2flux-monthgrid-v5-202110>
<Item id=eccodarwin-co2flux-monthgrid-v5-202109>
<Item id=eccodarwin-co2flux-monthgrid-v5-202108>
<Item id=eccodarwin-co2flux-monthgrid-v5-202107>
<Item id=eccodarwin-co2flux-monthgrid-v5-202106>
<Item id=eccodarwin-co2flux-monthgrid-v5-202105>
<Item id=eccodarwin-co2flux-monthgrid-v5-202104>
<Item id=eccodarwin-co2flux-monthgrid-v5-202103>
<Item id=eccodarwin-co2flux-monthgrid-v5-202102>
<Item id=eccodarwin-co2flux-monthgrid-v5-202101># Examine the first item in the search results
# Keep in mind that a list starts from 0, 1, 2... therefore items[0] is referring to the first item in the list/collection
items[0]- type "Feature"
- stac_version "1.1.0"
stac_extensions[] 2 items
- 0 "https://stac-extensions.github.io/raster/v1.1.0/schema.json"
- 1 "https://stac-extensions.github.io/projection/v2.0.0/schema.json"
- id "eccodarwin-co2flux-monthgrid-v5-202212"
geometry
- type "Polygon"
coordinates[] 1 items
0[] 5 items
0[] 2 items
- 0 -180.125
- 1 -90.124826629681
1[] 2 items
- 0 179.875
- 1 -90.124826629681
2[] 2 items
- 0 179.875
- 1 89.875173370319
3[] 2 items
- 0 -180.125
- 1 89.875173370319
4[] 2 items
- 0 -180.125
- 1 -90.124826629681
bbox[] 4 items
- 0 -180.125
- 1 -90.124826629681
- 2 179.875
- 3 89.875173370319
properties
- end_datetime "2022-12-31T00:00:00+00:00"
- start_datetime "2022-12-01T00:00:00+00:00"
- datetime None
links[] 5 items
0
- rel "collection"
- href "https://earth.gov/ghgcenter/api/stac/collections/eccodarwin-co2flux-monthgrid-v5"
- type "application/json"
1
- rel "parent"
- href "https://earth.gov/ghgcenter/api/stac/collections/eccodarwin-co2flux-monthgrid-v5"
- type "application/json"
2
- rel "root"
- href "https://earth.gov/ghgcenter/api/stac"
- type "application/json"
- title "US GHG Center STAC API"
3
- rel "self"
- href "https://earth.gov/ghgcenter/api/stac/collections/eccodarwin-co2flux-monthgrid-v5/items/eccodarwin-co2flux-monthgrid-v5-202212"
- type "application/geo+json"
4
- rel "preview"
- href "https://earth.gov/ghgcenter/api/raster/collections/eccodarwin-co2flux-monthgrid-v5/items/eccodarwin-co2flux-monthgrid-v5-202212/WebMercatorQuad/map?assets=co2&nodata=nan&rescale=-0.0007%2C0.0002&colormap_name=bwr"
- type "text/html"
- title "Map of Item"
assets
co2
- href "s3://ghgc-data-store/eccodarwin-co2flux-monthgrid-v5/ECCO-Darwin_CO2_flux_202212.tif"
- type "image/tiff; application=geotiff"
- title "Air-Sea CO₂ Flux"
- description "Monthly mean air-sea CO₂ flux (negative into ocean)."
proj:bbox[] 4 items
- 0 -180.125
- 1 -90.124826629681
- 2 179.875
- 3 89.875173370319
proj:shape[] 2 items
- 0 721.0
- 1 1440.0
raster:bands[] 1 items
0
- scale 1.0
- offset 0.0
- sampling "area"
- data_type "float64"
histogram
- max 1e+20
- min -0.0560546528687938
- count 11.0
buckets[] 10 items
- 0 338606.0
- 1 0.0
- 2 0.0
- 3 0.0
- 4 0.0
- 5 0.0
- 6 0.0
- 7 0.0
- 8 0.0
- 9 186706.0
statistics
- mean 3.554192556042885e+19
- stddev 4.786401658343999e+19
- maximum 1e+20
- minimum -0.0560546528687938
- valid_percent 0.0001903630604288499
proj:geometry
- type "Polygon"
coordinates[] 1 items
0[] 5 items
0[] 2 items
- 0 -180.125
- 1 -90.124826629681
1[] 2 items
- 0 179.875
- 1 -90.124826629681
2[] 2 items
- 0 179.875
- 1 89.875173370319
3[] 2 items
- 0 -180.125
- 1 89.875173370319
4[] 2 items
- 0 -180.125
- 1 -90.124826629681
proj:projjson
id
- code 4326.0
- authority "EPSG"
- name "WGS 84"
- type "GeographicCRS"
datum
- name "World Geodetic System 1984"
- type "GeodeticReferenceFrame"
ellipsoid
- name "WGS 84"
- semi_major_axis 6378137.0
- inverse_flattening 298.257223563
- $schema "https://proj.org/schemas/v0.4/projjson.schema.json"
coordinate_system
axis[] 2 items
0
- name "Geodetic latitude"
- unit "degree"
- direction "north"
- abbreviation "Lat"
1
- name "Geodetic longitude"
- unit "degree"
- direction "east"
- abbreviation "Lon"
- subtype "ellipsoidal"
proj:transform[] 9 items
- 0 0.25
- 1 0.0
- 2 -180.125
- 3 0.0
- 4 -0.24965325936199723
- 5 89.875173370319
- 6 0.0
- 7 0.0
- 8 1.0
- proj:code "EPSG:4326.0"
roles[] 2 items
- 0 "data"
- 1 "layer"
rendered_preview
- href "https://earth.gov/ghgcenter/api/raster/collections/eccodarwin-co2flux-monthgrid-v5/items/eccodarwin-co2flux-monthgrid-v5-202212/preview.png?assets=co2&nodata=nan&rescale=-0.0007%2C0.0002&colormap_name=bwr"
- type "image/png"
- title "Rendered preview"
- rel "preview"
roles[] 1 items
- 0 "overview"
- collection "eccodarwin-co2flux-monthgrid-v5"
# Restructure our items into a dictionary where keys are the datetime items; we can then query more easily by date/time, e.g. "2020-02"
items_dict = {item.properties["start_datetime"][:7]: item for item in collection.get_items()}Next, you will examine the contents of the collection under the temporal variable. You’ll see that the data is available from January 2020 to December 2022. Looking at the dashboard:time density, you can observe that the data is periodic with monthly time density.
# Before we go further, let's pick which asset to focus on for the remainder of the notebook.
# For this collection, there is only one asset to choose from: "co2".
asset_name = "co2"Create Maps Using Folium
You will now explore differences in Air-Sea CO₂ flux at two different date/times. You will visualize the outputs on a map using folium.
Fetch Imagery from Raster API
Here we get information from the Raster API, which we will add to our map in the next section.
Below, you will specify the upper and lower bounds of your desired colorbar for visualizing the data, which will be saved as rescale_values.
# Specify two dates/times to visualize.
dates = ["2020-01","2020-07"]observation_date_1 = items_dict[dates[0]]
# Extract collection name and item ID
collection_id = observation_date_1.collection_id
item_id = observation_date_1.idobject = observation_date_1.assets[asset_name]
raster_bands = object.extra_fields.get("raster:bands", [{}])
raster_bands[{'scale': 1.0,
'offset': 0.0,
'sampling': 'area',
'data_type': 'float64',
'histogram': {'max': 1e+20,
'min': -0.0035127835016991096,
'count': 11.0,
'buckets': [338606.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 186706.0]},
'statistics': {'mean': 3.554192556042885e+19,
'stddev': 4.786401658343999e+19,
'maximum': 1e+20,
'minimum': -0.0035127835016991096,
'valid_percent': 0.0001903630604288499}}]rescale_values = {
"max": raster_bands[0]['statistics']['mean'] + 2*raster_bands[0]['statistics']['stddev'],
"min": raster_bands[0].get("histogram", {}).get("min"),
}
print(rescale_values){'max': 1.3126995872730884e+20, 'min': -0.0035127835016991096}Now, you will pass the item id, collection name, asset name, and the rescale_values to the Raster API endpoint, along with a colormap. This step is done twice, one for each date/time you will visualize, and tells the Raster API which collection, item, and asset you want to view, specifying the colormap and colorbar ranges to use for visualization. The API returns a JSON with information about the requested image. Each image will be referred to as a tile.
# Choose a colormap for displaying the data
# Making sure that capitalization follows Matplotlib standards
# For more information on Colormaps in Matplotlib, please visit https://matplotlib.org/stable/users/explain/colors/colormaps.html
color_map = "magma"# Make a GET request to retrieve information for the date mentioned below
tile_matrix_set_id = "WebMercatorQuad"
observation_date_1_tile = requests.get(
f"{RASTER_API_URL}/collections/{collection_id}/items/{item_id}/{tile_matrix_set_id}/tilejson.json?"
f"&assets={asset_name}"
f"&color_formula=gamma+r+1.05&colormap_name={color_map}"
f"&rescale=-0.0007,0.0007"
).json()
# Print the properties of the retrieved granule to the console
observation_date_1_tile{'tilejson': '2.2.0',
'version': '1.0.0',
'scheme': 'xyz',
'tiles': ['https://earth.gov/ghgcenter/api/raster/collections/eccodarwin-co2flux-monthgrid-v5/items/eccodarwin-co2flux-monthgrid-v5-202001/tiles/WebMercatorQuad/{z}/{x}/{y}@1x?assets=co2&color_formula=gamma+r+1.05&colormap_name=magma&rescale=-0.0007%2C0.0007'],
'minzoom': 0,
'maxzoom': 24,
'bounds': [-180.125, -90.124826629681, 179.875, 89.875173370319],
'center': [-0.125, -0.1248266296809959, 0]}# Make a GET request to retrieve information for the date mentioned below
observation_date_2 = items_dict[dates[1]]
# Extract collection name and item ID
collection_id = observation_date_2.collection_id
item_id = observation_date_2.id
observation_date_2_tile = requests.get(
f"{RASTER_API_URL}/collections/{collection_id}/items/{item_id}/{tile_matrix_set_id}/tilejson.json?"
f"&assets={asset_name}"
f"&color_formula=gamma+r+1.05&colormap_name={color_map}"
f"&rescale=-0.0007,0.0007"
).json()
# Print the properties of the retrieved granule to the console
observation_date_2_tile{'tilejson': '2.2.0',
'version': '1.0.0',
'scheme': 'xyz',
'tiles': ['https://earth.gov/ghgcenter/api/raster/collections/eccodarwin-co2flux-monthgrid-v5/items/eccodarwin-co2flux-monthgrid-v5-202007/tiles/WebMercatorQuad/{z}/{x}/{y}@1x?assets=co2&color_formula=gamma+r+1.05&colormap_name=magma&rescale=-0.0007%2C0.0007'],
'minzoom': 0,
'maxzoom': 24,
'bounds': [-180.125, -90.124826629681, 179.875, 89.875173370319],
'center': [-0.125, -0.1248266296809959, 0]}Generate Map
We’ll look at Air-Sea CO2 fluxes off the Northeast coast of the U.S. for two dates.
# Initialize the map, specifying the center of the map and the starting zoom level.
# 'folium.plugins' allows mapping side-by-side via 'DualMap'
# Map is centered on the position specified by "location=(lat,lon)"
map_ = folium.plugins.DualMap(location=(41,-67), zoom_start=5)
# Define the first map layer using the tile fetched for the first date
# The TileLayer library helps in manipulating and displaying raster layers on a map
map_layer_1 = TileLayer(
tiles=observation_date_2_tile["tiles"][0], # Path to retrieve the tile
attr="US GHG Center", # Set the attribution
name=f'{dates[0]} {items_dict[dates[1]].assets[asset_name].title}', # Title for the layer
overlay=True, # The layer can be overlaid on the map
opacity=0.8, # Adjust the transparency of the layer
)
# Add the first layer to the Dual Map
# This will appear on the left side, specified by 'm1'
map_layer_1.add_to(map_.m1)
# Define the second map layer using the tile fetched for the second date
map_layer_2 = TileLayer(
tiles=observation_date_1_tile["tiles"][0], # Path to retrieve the tile
attr="US GHG Center", # Set the attribution
name=f'{dates[1]} {items_dict[dates[1]].assets[asset_name].title}', # Title for the layer
overlay=True, # The layer can be overlaid on the map
opacity=0.8, # Adjust the transparency of the layer
)
# Add the second layer to the Dual Map
# This will appear on the right side, specified by 'm2'
map_layer_2.add_to(map_.m2)
# Add data markers to both sides of map
folium.Marker((41,-67)).add_to(map_)
# Add controls to turn different elements on/off, for both sides of map
folium.LayerControl(collapsed=False).add_to(map_)
# Add colorbar
# First, scale our colorbar range to make the numbers display more neatly
for k in rescale_values.keys():
rescale_values[k] = rescale_values[k]/1e19
# Next, call one of the custom 'ghgc_utils' functions to create an HTML colorbar representation
legend_html = ghgc_utils.generate_html_colorbar(
color_map,
rescale_values,
label='10^19 Millimoles per meter squared per second (mmol m²/s)'
)
# Add colorbar to the map
map_.get_root().html.add_child(folium.Element(legend_html))
# Visualize the Dual Map
map_Make this Notebook Trusted to load map: File -> Trust Notebook
Calculate Zonal Statistics
To perform zonal statistics, you first need to create a polygon. In this use case, you are creating a polygon along the coast of California, United States.
# Give your AOI a name for use in the plot later
aoi_name = 'Coastal California'
# Define AOI as a GeoJSON
aoi = {
"type": "Feature", # Create a feature object
"properties": {},
"geometry": { # Set the bounding coordinates for the polygon
"coordinates": [
[
[-124.19, 37.86], # Northwest bounding coordinate
[-123.11, 37.86], # Northeast bounding coordinate
[-119.96, 33.16], # Southeast bounding coordinate
[-121.13, 33.16], # Southwest bounding coordinate
[-124.19, 37.86] # Northwest bounding coordinate (closing the polygon)
]
],
"type": "Polygon",
},
}Now that you created the polygon for the area of interest, you need to develop a function that runs through the data collection and generates the statistics for a specific item (granule) within the boundaries of the AOI polygon.
Before you run the generated function in the previous step on a specific item (observation), you need to check the total number of items available within the collection and retrieve the information regarding their start date-time.
# Check the total number of items available within the collection
#items = requests.get(
# f"{STAC_API_URL}/collections/{collection_name}/items?limit=600"
#).json()["features"]
#
## Print the total number of items (granules) found
#print(f"Found {len(items)} items")# Examine the first item in the collection
#items[0]['properties']Generate the statistics for the AOI
%%time
# Use one of the custom 'ghgc_utils' functions to generate statistics over your AOI using the Raster API
# The result is output as a Pandas DataFrame
# This step may take a minute
df = ghgc_utils.generate_stats(items,aoi,url=RASTER_API_URL,asset=asset_name)
# Display the stats for the first 5 rows in the DataFrame
df.head(5)Generating stats...
Done!
CPU times: total: 328 ms
Wall time: 16.9 s| datetime | min | max | mean | count | sum | std | median | majority | minority | unique | histogram | valid_percent | masked_pixels | valid_pixels | percentile_2 | percentile_98 | date | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2022-12-01T00:00:00+00:00 | -0.00010515466364758998 | -0.00002633915608704389 | -0.00006713517054587462 | 86.62000274658203125000 | -0.00581524865707591307 | 0.00001997011065738988 | -0.00006633380711657132 | -0.00010515466364758998 | -0.00010515466364758998 | 115.00000000000000000000 | [[9, 8, 9, 8, 22, 10, 18, 16, 8, 7], [-0.00010... | 94.26000000000000511591 | 245.00000000000000000000 | 115.00000000000000000000 | -0.00010359588859230771 | -0.00003194067887033325 | 2022-12-01 00:00:00+00:00 |
| 1 | 2022-11-01T00:00:00+00:00 | -0.00005327701115205930 | 0.00001028134560749642 | -0.00002951114864331012 | 86.62000274658203125000 | -0.00255625577653831359 | 0.00001407494890675066 | -0.00003181141450025719 | -0.00005327701115205930 | -0.00005327701115205930 | 115.00000000000000000000 | [[6, 21, 17, 16, 13, 15, 11, 9, 5, 2], [-5.327... | 94.26000000000000511591 | 245.00000000000000000000 | 115.00000000000000000000 | -0.00005065607151994821 | -0.00000110899758273440 | 2022-11-01 00:00:00+00:00 |
| 2 | 2022-10-01T00:00:00+00:00 | -0.00003414260442530581 | 0.00004739613790624944 | -0.00000174851221190252 | 86.62000274658203125000 | -0.00015145613259742822 | 0.00001837792521916367 | -0.00000250581129329143 | -0.00003414260442530581 | -0.00003414260442530581 | 115.00000000000000000000 | [[10, 15, 16, 13, 14, 15, 14, 12, 3, 3], [-3.4... | 94.26000000000000511591 | 245.00000000000000000000 | 115.00000000000000000000 | -0.00003200012649207952 | 0.00003440232174632397 | 2022-10-01 00:00:00+00:00 |
| 3 | 2022-09-01T00:00:00+00:00 | -0.00004692151229820521 | 0.00004959876485207447 | -0.00000688822897101456 | 86.62000274658203125000 | -0.00059665841238836686 | 0.00002092700549779860 | -0.00000422793679848356 | -0.00004692151229820521 | -0.00004692151229820521 | 115.00000000000000000000 | [[6, 13, 20, 14, 17, 12, 24, 5, 1, 3], [-4.692... | 94.26000000000000511591 | 245.00000000000000000000 | 115.00000000000000000000 | -0.00004511987338653629 | 0.00002716666299628972 | 2022-09-01 00:00:00+00:00 |
| 4 | 2022-08-01T00:00:00+00:00 | -0.00009080547748822169 | -0.00000155375716192473 | -0.00003822837370543178 | 86.62000274658203125000 | -0.00331134183536186495 | 0.00002081685202185498 | -0.00003259453885688862 | -0.00009080547748822169 | -0.00009080547748822169 | 115.00000000000000000000 | [[2, 10, 4, 8, 11, 15, 21, 20, 12, 12], [-9.08... | 94.26000000000000511591 | 245.00000000000000000000 | 115.00000000000000000000 | -0.00008052887732505406 | -0.00000747190884265286 | 2022-08-01 00:00:00+00:00 |
Time-Series Analysis
You can now explore the fossil fuel emissions using this data collection (January 2020 -December 2022) for the Coastal California region. You can plot the data set using the code below:
# Sort the DataFrame by the datetime column so the plot displays the values from left to right (2020 -> 2022)
df_sorted = df.sort_values(by="datetime")
# Change which_stat to reflect which statistic you want to visualize in your time series plot - mean, min, max, etc.
which_stat = "max"
# Plot the timeseries analysis of the monthly air-sea CO₂ flux changes over the AOI
# Figure size: width of 10, height of 5
fig = plt.figure(figsize=(10,5))
plt.plot(
[d[0:7] for d in df_sorted["datetime"]], # X-axis: sorted datetime, showing YYYY-MM only
df_sorted[which_stat], # Y-axis: maximum CO₂ value
color="#118AB2", # Line color, in hex format
linestyle="-", # Line style
linewidth=2, # Line width
label=f"{items[0].assets[asset_name].title}", # Legend label
)
# Set axis labels
plt.xlabel("Month")
plt.ylabel(f"{items[0].assets[asset_name].title} (mmol m²/s)")
# Rotate x-axis labels to avoid cramping
plt.xticks(rotation=45,ha='right')
# Set plot title
plt.title(f"{which_stat.capitalize()} {items[0].assets[asset_name].title} for {aoi_name} (2020-2022)")
# Insert legend
plt.legend()
# Add data citation
plt.text(
min([d[0:7] for d in df_sorted["datetime"]][:]), # X-coordinate of the text (first datetime value)
df_sorted[which_stat].min(), # Y-coordinate of the text (minimum CO2 value)
# Text to be displayed
f"{collection.title}",
fontsize=9, # Font size
horizontalalignment="left", # Horizontal alignment
verticalalignment="bottom", # Vertical alignment
color="blue", # Text color
)
# Display the plot
plt.show()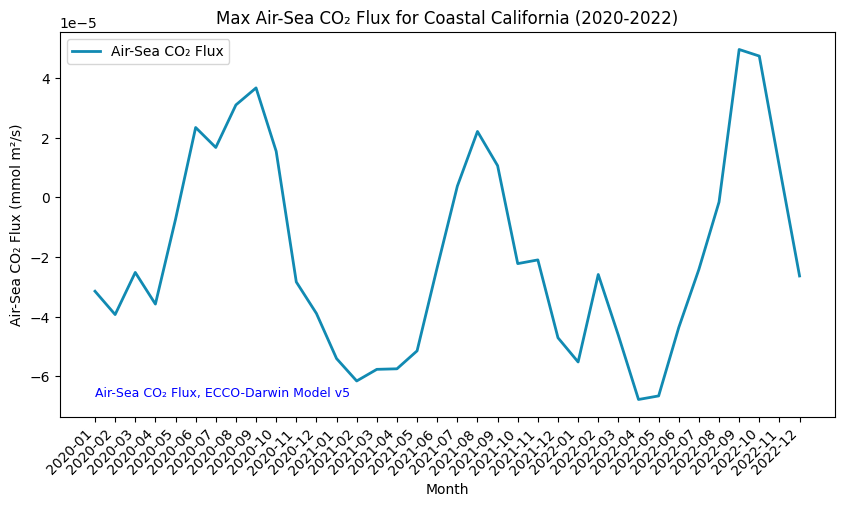
Here we can see the seasonal cycle of air-sea CO2 flux off the coast of California over the three relevant years.
Summary
In this notebook, we have successfully completed the following steps for the Air-Sea CO₂ Flux, ECCO-Darwin Model v5 dataset:
- Install and import the necessary libraries
- Fetch the collection from STAC using the appropriate endpoints
- Count the number of existing files (granules) within the collection
- Map and compare the CO₂ Flux levels over the Coastal California area for two distinctive dates
- Generate zonal statistics for an area of interest (AOI)
- Generate a time-series graph of the CO₂ Flux values for a specified region
If you have any questions regarding this user notebook, please contact us using the feedback form.